.svg)

A journey from traditional stack to a new generation AI — and why safe autonomy demands layered intelligence over a single model.
In our 10 years of history, we have rebuilt our self-driving AI from the ground up three times:
Era 1: Vision Only
From our founding in San Jose, California in 2016, we pioneered a vision-only, end-to-end self-driving stack. Starting in 2016, this camera-first approach proved that end-to-end city driving was possible without the crutch of HD maps or high-precision lidar. It was a significant milestone, yet it ultimately lacked the uncompromising reliability required for true Level 4 fully driverless operations. While the end-to-end approach demonstrated a high performance ceiling, its minimum reliability floor remained unguaranteed.
Era 2: Traditional Lidar-based System
To bridge that gap, we entered a second era: building a modular, lidar-based system grounded in traditional autonomous driving frameworks, with some small deep learning models to power certain task components such as perception and prediction. This provided the interpretability and robustness needed to reach our first fully driverless deployment in 2020. However, this architecture predated the transformative breakthroughs emerging from the latest frontier of artificial intelligence.
Era 3: The Thinking Agent
The debut of the first multimodal LLM and the first reasoning model served as a catalyst for our team to completely reimagine our autonomy software. The physical AI industry has undergone a fundamental architectural shift with the arrival of multimodal foundation models with reasoning capability for agentic use cases. By leveraging advancements in large model training and agentic AI, we engineered a comprehensive AI built for the highest level of safety. The result is Tensor Gradient — a new era for our autonomy technology.
Opting to rebuild from a clean sheet is a difficult strategic decision, as established systems often transform into legacy constraints that stifle innovation. While it is inherently simpler to maintain momentum through incremental updates, such mature frameworks frequently outperform nascent architectures in their early stages. We have repeatedly chosen the rebuild—committing to the difficult yet necessary path of fundamental rebuilding to ensure our technology remains at the frontier.
Tensor Gradient represents the first self-driving AI to synthesize the strengths of diverse AI approaches, overcoming the weaknesses of any single method through layered intelligence.
Autonomous driving will not scale by relying on a single model to solve every driving scenario. It requires systems that can perceive, reason, adapt, and make decisions under uncertainty — on real roads, in real traffic, across the messy long tail of the physical world.
Our team made a decision that most teams avoid: we stopped patching our old traditional AD stack, and started over with a data-driven learning approach in every component and every layer. Tensor Gradient is the result — a completely new self-driving AI, designed and written from scratch. It is not an iteration. It is a new architecture. Almost all of the code in Tensor Gradient is completely newly written, built around a single conviction: that safe, scalable Level 4 autonomy is not one model, but a layered intelligence — each layer with a defined role, a fallback, and a reason to exist.
Tensor Gradient is organized as five layers. The top layers give the vehicle humanlike reasoning and end-to-end fluency. The middle layer gives it precise, interpretable, map-aware planning. The bottom two layers exist for one purpose only: to make sure that when something goes wrong, the Tensor Robocar still does the right thing.
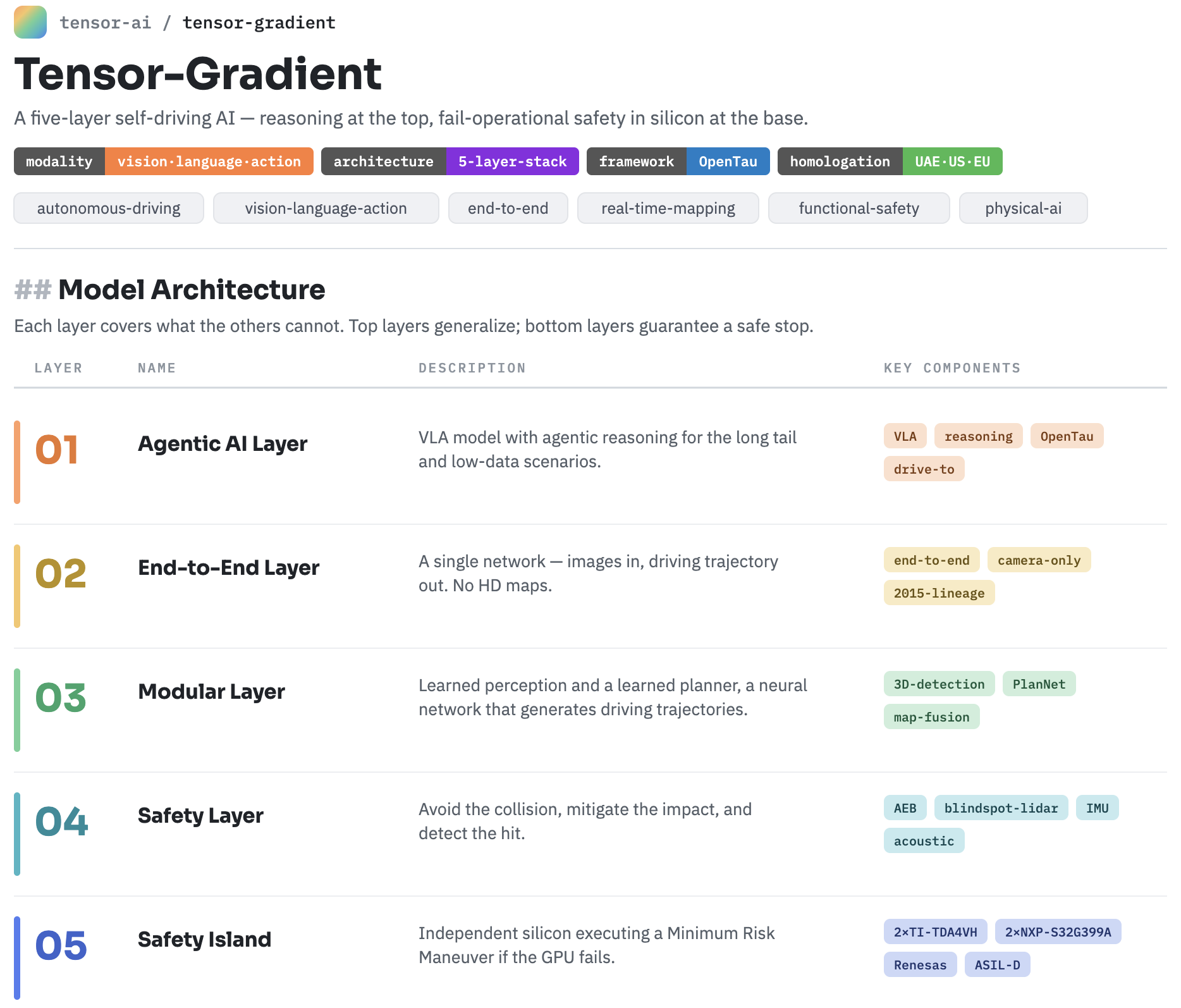
This post walks through all five.
At the top of Tensor Gradient sits the Agentic AI layer, built on a vision-language-action (VLA) model with agentic reasoning capability. Where a conventional driving model maps sensors to trajectories, our VLA model goes further — it reasons, plans, and acts across the driving task, bringing humanlike perception and decision-making to situations that have no clean precedent in the training data.
This is the layer that earns its keep in the hard cases: ambiguous construction zones, gestures from a traffic officer, an unusual detour, or scenarios the fleet has simply never seen enough of to learn statistically. Instead of failing silently or freezing, the agentic layer can interpret intent, weigh options, and explain its choices — providing the interpretability that is critical for safety validation and regulatory collaboration. This agentic approach is particularly adept at handling the long tail where in-house driving data is sparse. For example, our Robocars can recognize UAE traffic signs in Arabic without vast amounts of local street sign data, leveraging Vision-Language Models (VLM) pre-trained on massive Internet-scale datasets.
While VLM and VLA models are remarkably powerful, they are traditionally too computationally expensive for the real-time demands of autonomous driving. The 8000-TOPS Tensor Supercomputer is the solution to this latency challenge. Powered by eight NVIDIA Thor-X GPUs, we run sophisticated VLA models locally, ensuring that high-level reasoning never comes at the cost of responsiveness or model complexity.
The Agentic AI layer serves as the intelligence engine for all agentic interactions within the Tensor Robocar, epitomized by our pioneering drive-to capability. Riders are no longer tethered to map pins or static addresses; they can simply articulate a destination in natural language—"pull up next to the blue awning past the second crosswalk"—and the vehicle leverages its multimodal stack to ground that intent in the physical world. By synthesizing perception, language, and action into a single unified model, the Robocar reasons through the environment to identify and navigate to the precise spot requested. To our knowledge, this represents the world's first deployment of a self-driving system capable of interpreting verbal cues to navigate dynamic, real-world surroundings on the fly.
Besides having powerful VLA models, it is perhaps equally or more important to have the right harness engineering. Beyond prompt engineering to ask the right question, or context engineering to provide the relevant context or reading the right sensor input to deploy the right tool use and MCP function calls, but to verify the results and validate the precondition while ensuring safety and user experience. Our team has spent a very significant amount of time engineering the right harness suitable for a Level-4 fully driverless robocar. We explored through multiple agent vs. single agent frameworks, to strive for the right balance between performance, context window size and latency.
We don't believe the path to reasoning-based autonomy should be closed. Alongside Tensor Gradient, we have released OpenTau, an open-source framework for training vision-language-action models for driving. OpenTau gives the broader research and developer community the building blocks to train, fine-tune, and evaluate agentic driving models — lowering the barrier to reasoning-based AVs the same way open foundation models lowered it for language. OpenTau also supports the state-of-the-art Reinforcement Learning training methods.
Know more at: https://www.tensor.auto/blog-events/opentau
The Tensor World Model is a frontier generative model designed to solve the data bottleneck for Physical AI by generating hyper-realistic, physically grounded synthetic data. By simulating diverse environments and rare edge cases for large-scale autonomous driving validation, it ensures continuous self-directed improvement and establishes a rigorous safety benchmark for the AI.

Beneath the agentic layer is a fully end-to-end model — a single neural network, one segment, no hand-coded intermediate representations. It takes camera images as input and produces driving trajectories as output, directly. There is no separately engineered perception-to-prediction-to-planning handoff inside it; the network learns the entire mapping from what the car sees to how it should move.
This is autonomy in its most distilled form. Trained on the scale and diversity of real-world driving Tensor has collected, the end-to-end model delivers smooth, humanlike driving for the overwhelming majority of everyday miles — the kind of fluent, continuous behavior that emerges only when a single network is allowed to learn the whole task, rather than being constrained by the seams between modules. It is fast, it is general, and it gets better with every mile of local data.
The model in this layer is new. The conviction behind it is not. Tensor has been pushing the frontier of large, end-to-end models for Physical AI for more than a decade. In 2015, our founder published DeepDriving at ICCV — a landmark paper, since cited more than 2,700 times, that was among the first to apply deep learning to self-driving on city streets and one of the earliest successful demonstrations of a fully end-to-end approach. Rather than leaning on hand-engineered rules or high-definition maps, it took raw images, ran them through a large neural network, and produced both map-level information and driving outputs in real time — an early glimpse of everything end-to-end models would become.
In March 2017, we went further: a fully end-to-end system that navigated real city streets in San Jose and mountain roads in Saratoga, cameras only — no lidar, no radar, no ultrasonics, no differential GPS, and no HD maps. It was the first system in the world to demonstrate vision-only, end-to-end self-driving in real city traffic, running day and night on a handful of low-cost webcams while making turns, handling traffic, yielding to pedestrians, driving in rain, and crossing highways, arterials, and residential streets. We patented the approach in July 2017 around a principle that still defines our work: end-to-end autonomous driving without dependence on high-definition or 3D maps.
Tensor Gradient's end-to-end layer is the modern expression of that decade-old principle — rebuilt at a completely different scale. Today's model carries far more parameters and far greater capability than anything that came before it, yet the core idea is unchanged: no HD maps, only high-level, turn-by-turn navigation instructions, with the network learning everything else directly from what it sees. The result is on the road now, driving across a wide range of environments in California and Dubai.
End-to-end models are powerful, but for the cases where we need transparency, traceability, and provable behavior, Tensor Gradient also runs a fully modular, ML-learned AI with explicit perception and planning components. This is the layer engineers can inspect, the layer where every decision can be traced to an input.
Perception is built on the latest transformer-based 3D scene understanding models, producing rich, structured estimates of the agents and objects around the vehicle—including vehicles, cyclists, and vulnerable road users—in three dimensions, frame by frame. Beyond cameras, lidars, and radars, the Tensor Robocar is equipped with four pairs of external directional microphones, enabling our multimodal large models to synthesize spatial audio for tracking sirens from emergency vehicles such as ambulances, fire trucks, and police cars.
Precise sensor calibration remains a critical bottleneck for physical AI. Beyond static factory-floor calibration, we have engineered an end-to-end neural network learning algorithm to adjust calibration parameters on the fly, transcending the limitations of traditional geometric computer vision to ensure the AI maintains a high-fidelity representation of the world at all times.
Planning is handled by PlanNet, a neural network that takes perception output and generates multiple candidate planning trajectories rather than a single guess. PlanNet is a joint prediction-and-planning model: it reasons about how the ego vehicle should move and how surrounding agents will respond at the same time, because in real traffic those two questions cannot be separated.
PlanNet's architecture is inspired by a game-theoretic, level-k reasoning formulation, letting it simulate how each agent — including the Robocar itself — adjusts its behavior in response to the predicted behavior of others. Key enhancements we built on top of it include:
Deployed on Tensor Robocars, PlanNet runs at real-time latency in parallel with our marginal prediction models — adding no overhead to the pipeline — and it measurably beats strong competing methods such as MultiPath++ for 10% on the 8-second planning task and 42% improvement on vehicle prediction.
This modular AI uses HD maps — but it does not depend on a perfectly maintained, always-current offline map, which is one of the biggest barriers to scaling any L4 fleet. Instead, Tensor Gradient generates the map on the fly, in real time, through an online map fusion network.
The fusion network treats the offline HD map as a strong prior, not gospel. It fuses that prior with live sensor data in a bird's-eye-view representation, and learns when to trust the map and when to trust its eyes. When the world has changed (a new construction layout, a removed lane, an unmarked turn lane, low-light or occluded markings), the network detects the change and patches a corrected map in real time. When the vehicle leaves mapped territory entirely, the network gracefully degrades to pure sensor-based online mapping and keeps driving.
Trained on millions of sensor frames — augmented with simulated, realistic structural map changes to close the sim-to-real gap — the fusion model reaches average precision of 99.56% (lane boundary), 99.78% (road boundary), and 99.40% (crosswalk) with the HD-map prior fused in, and runs at 40 ms per frame. The result: a fleet that scales without a fleet of map editors chasing it.
Reasoning and planning keep the vehicle out of trouble. Layer 4 exists for the moments when physics is closing in anyway.
The Tensor Robocar is undergoing homologation to UAE, US, and EU standards — all of which set a high bar for automatic emergency braking. To clear that bar, we built a new, AI-based AEB system from scratch, and made full use of our in-house Tensor Sentinel Blindspot Lidar to see threats that camera-only systems miss, including at the close range and wide angles where vulnerable road users and cut-ins appear.
The safety layer is organized around three escalating responsibilities:
This is a layer designed under the assumption that the layers above it have already failed — and built to perform anyway.
The final layer answers the hardest question in autonomy: what happens if the main brain dies?
If the primary NVIDIA GPU compute crashes, Tensor's supercomputer does not go dark. A dedicated safety island — built on two Texas Instruments TDA4VH processors and two NXP S32G399A processors — forms a simpler, independent automated driving system whose job is to execute a Minimum Risk Maneuver (MRM): bring the vehicle safely to a controlled stop in a Minimum Risk Condition (MRC), even with the main compute gone.
This is genuine redundancy in hardware, sourced from the industry's most trusted automotive silicon:
Together, TI, NXP, and Renesas give the Tensor supercomputer a safety architecture that does not depend on any single point of failure — the difference between an autonomous vehicle that usually works and one that is safe to deploy.
A central challenge in this layered architecture is the orchestration of the AI. Drawing a parallel to Reinforcement Learning from Human Feedback (RLHF) in large language models, our system generates multiple candidate trajectories which are then evaluated by a trained Reward Model. This selection process scores each proposal against a rigorous set of criteria—including safety, passenger comfort, and strict adherence to traffic laws—to determine the optimal path. This data-driven scoring ensures that decision-making is not rule-based, but learned from the best driving outcomes. For ultimate redundancy, a safety monitor continuously tracks the "heartbeat" of every layer; should an anomaly be detected, Layer 5 immediately intervenes to bring the vehicle to a Minimum Risk Condition.
Each layer of Tensor Gradient covers what the others cannot. The agentic VLA layer reasons through the long tail. The end-to-end model drives fluently through the everyday. The modular layer plans transparently and maps the world in real time. The safety layer acts when physics runs out. And the safety island stands behind all of it in silicon.
No single model drives the world. A well-designed system does. Tensor Gradient — over 90% new code, built from a clean sheet — is that system.
Rebuilding from the ground up is a hard choice, because established systems often become legacy constraints that stifle innovation. The true challenge lies in the research taste & judgment required to determine when a new approach has the potential to supersede a proven architecture. We have built the infrastructure for continuous evolution: training, simulation, iterations, and even full architectural rebuilds. At present, critical evaluations of research trajectory and technical intuition remains a human endeavor — one that is increasingly becoming the primary bottleneck of our development pace. Our next frontier: engineering systems capable of self-improvement and autonomous redesign.
Tensor Gradient powers the Tensor Robocar. OpenTau, our open-source VLA training framework, is available to the developer and research community.


Sign up to get the latest news, announcements and
updates direct to your inbox.
.webp)





.svg)




